Language Report
This page shows my evaluation of language similarity. My data comes from the Similarity Database of Modern Lexicons developed by the DataScientia Foundation.
Language Map of Europe
Here I used gradient descent to position European languages on a map in such a way as to correlate the distance each language is from another most perfectly with the actual level of similarity languages have with each other. The map shows exactly what one would expect: Romance languages clustered together, slavic languages clustered together, and germanic languages clustered together. Since english is a creole of germanic languages and romance languages, it occupies a fairly central location (along with Dutch), so I guess it is good that English ended up being the lingua franca.

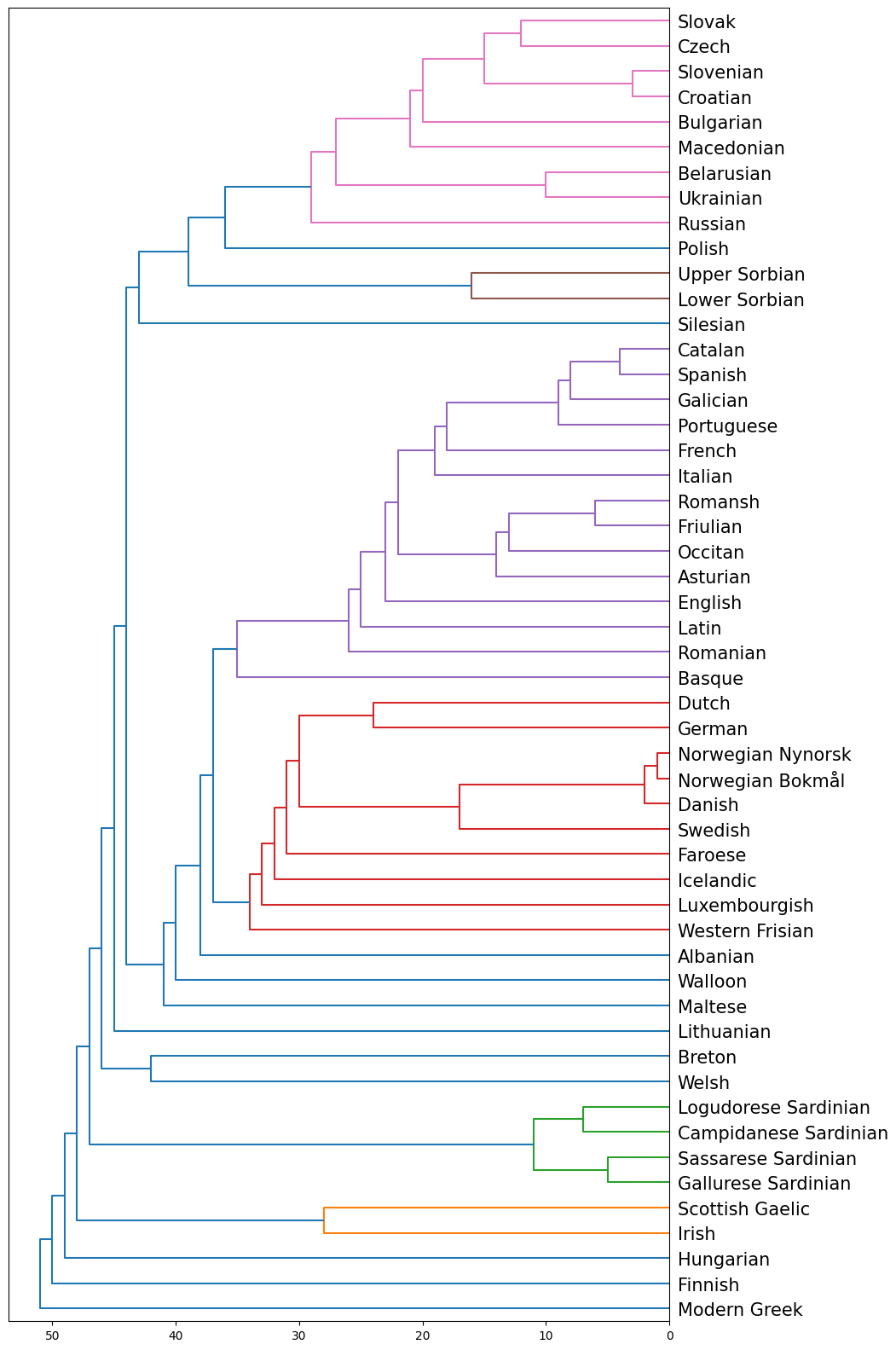
Dendrogram European Languages
Here is a clustering dendrogram of european languages by similarity. In this dendrogram, I used the Single Linkage method (or minimum linkage). This means that the distance between two clusters is defined as the shortest distance between any two points, one from each cluster.
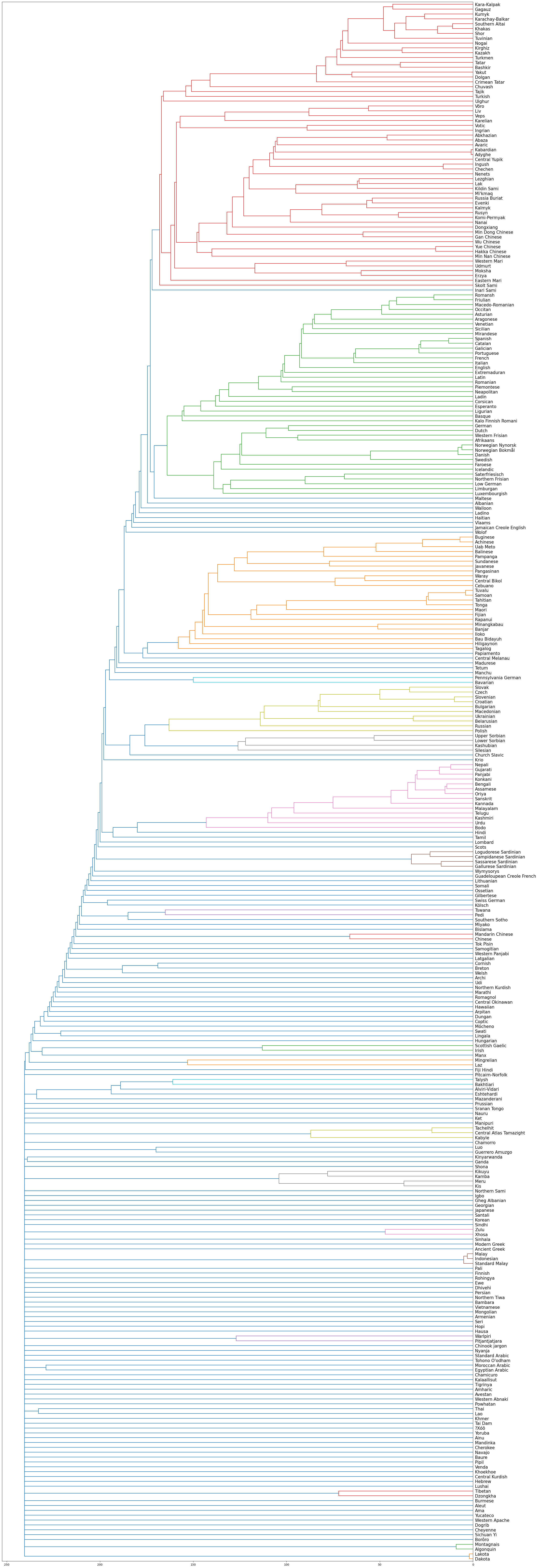
Dendrogram World Languages
This is a repetition of the previous Dendrogram, but instead using all languages.
Source Code
This is a link to code used in producing these statistics.
It's very disorganized, I apologize.
languageSimilarity